
Optimising Confluence performance on SQL Server 2014
Internally we have a Confluence wiki for our knowledge base. Confluence is regarded as the market leader for wiki systems out there and we enjoy using it internally.
The site is running on a single Windows Server 2012 R2 Azure VM with SQL Server 2014 SP1. While confluence’s native database is Postgres, it can work on SQL Server. However over time we found out some optimisations are required.
For a while, we had performance issues with the site that often over time, ended up with either the site hanging or crashing.
After some internal investigations and tickets with Atlassian, there are some optimisations I can suggest if you are encountering similar issues:
Set the database to simple recovery model
After just over a year of use and less than 100 users, the log file for the database was 6GB! This is exceptionally large and made backups and restores very time consuming.
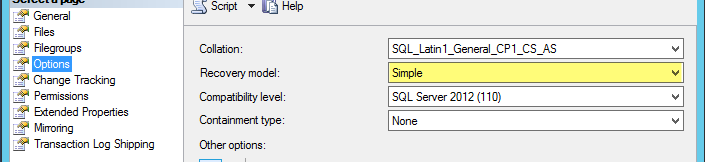
- Open SQL Server Management Studio
- Select the Confluence database, right click and select Properties
- Select Options and then set the Recovery Model to Simple.
(Don’t forget to shrink your database files afterwards!)
Increase the number of database connections
Looking at memory stack traces when performance was slow, we were able to determine that most of the thread bottlenecks were caused by multiple threads waiting for a database connection. It appears the default setting is just not enough.
In the file called confluence.cfg.xml located in the root of the Confluence Application Data folder.
There is a line defined as
<property name="hibernate.c3p0.max_size">30</property>
This defaults to 30, but it should be set to 90 or more. By setting it higher, we have noticed small performance increases and less bottlenecks.
<property name="hibernate.c3p0.max_size">90</property>
Hopefully these two optimisations can assist getting your confluence instance running smoothly. If there is anything else you can suggest, feel free to leave a comment!



Leave a comment